
Product Analytics Approach to Alternative Data
An impressive startup example and challenges ahead

I have written in the past about how external data is different from internal data science. External (alternative) data is often, but not exclusively, used by asset management and focused on measuring companies outside-in.1 Some techniques, such as nowcasting economic timeseries are perhaps unique today to external data users in asset management. External data users in all industries (CPG or pharmaceuticals, for example) focus more on solving data fidelity and availability issues than internal data scientists need to.
However, a new startup, called Motif2, recently released a product demo that inspired me to consider what is similar. The type of inference product managers extract about customer journeys is similar to what certain discretionary portfolio managers care about measuring. The video is worth a watch:
Motif - Bluesky data analysis - Watch Video
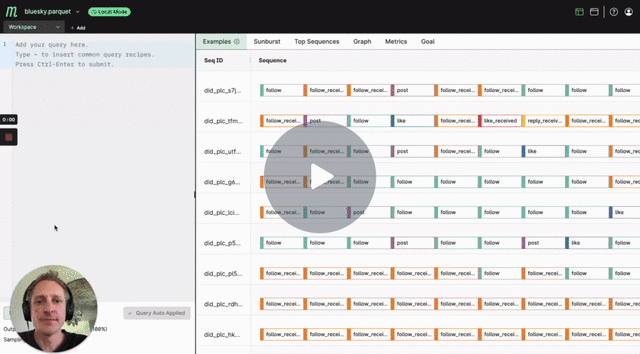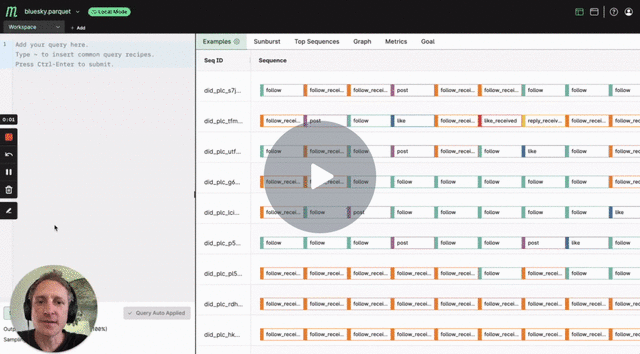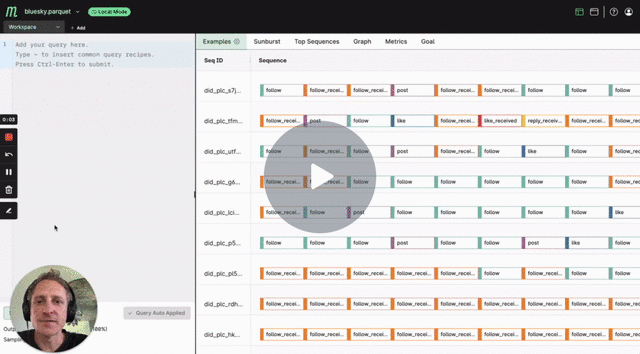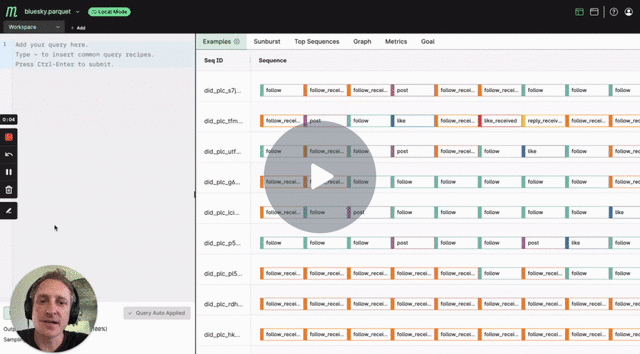
Sean uses BlueSky data3 – a Twitter alternative that makes their data public – to demonstrate the tool. His demo is aimed at growth analytics or data science professionals working with product managers. However, the relevance to anyone who has worked with third party external datasets4 is clear.
Product managers are presumably looking for ways to optimize features to drive a target behavior (signups, posts, checkouts etc.) Portfolio managers, particularly those with long-term mandates, are looking to find early indications that a new behavior is taking off, before it is obvious in top-line results. Among hedge fund data practitioners, it is safe to say that this is a consensus growth path for alternative data.
As DoorDash penetrates suburban and rural areas where pizza delivery used to be the only option, do consumers spend incrementally more on eating out? Or does Domino’s market-share erode? These types of questions, if they can be measured early, provide insight over horizons much longer than a quarter or two.
In practice, these questions are difficult for external data users for two reasons.
First, the perfect dataset is almost never available – the portfolio manager needs to jump across datasets that need to be linked together. A manager may want to know, for example, whether a new coffee brand is successfully taking share from in-grocery store coffee purchases. An analyst needs a transaction dataset and point-of-sale dataset that has joinable user IDs. Extend the question to estimate whether Instacart’s ads impact this decision, and suddenly they need an in-app or clickstream dataset as well. This type of data availability remains a key problem5.
Also, third party panel datasets are a convenience sample. Data is collected from consenting consumers or businesses. This immediately complicates any analysis as a user can churn from a panel at any time, so the analyst must simultaneously model user churn from the convenience sample versus user churn from the target analysis.6
Neither of these problems are generally true for internal product analytics because growth and data science teams have the entire population in question available. Nonetheless, Motif serves as a good inspiration for what could be done by a wide variety of teams not just with internal data, but with external data.
The other obvious example are brand or category managers at CPG firms. Similar to portfolio managers, these folks do not have direct access to first party sales data (since the transaction happens at retailers, not manufacturers) and so must rely on third party external data. I will use a portfolio manager in an asset management firm as the point of comparison here, but the point applies more generally.
External datasets such as credit card data, point-of-sale data, clickstream data, or app usage data all have the same essential properties as the BlueSky data: they are event logs tied to users over time.
And, this happens to be one of the key reasons I started Cybersyn. This data availability problem, again, is a broader issue that just in asset management. To use the CPG example again, a key missing dataset has been a link between SKU-level purchase panels and credit card data.
It will be interesting to see if Motif can accommodate this: one could imagine a “cohorts-in-cohorts” approach where you segment users first by their joining the convenience sample and then second in their first time taking some action, with a probabilistic correction for them having already taken that first action before their joining the sample.
Question Alex, what are applications of external data for a startup? A lot of the stuff you talk about is buy-side, but how can a startup benefit from external data? Use Cybersyn as an example, disregarding the business model of selling data, how does alternative data help you with marketing, sales, hiring, etc.