
Churn Paradox
And, why you might be calculating Net Dollar Retention wrong

There are three kinds of lies: lies, damned lies, and statistics.
— Mark Twain1
Simpson’s paradox is a famous statistical paradox taught in Statistics 101 classes2. The paradox can be illustrated with its most famous example: sex bias in admission to UC Berkeley. In 1973, 44% of male applicants were admitted to the PhD program they applied to whereas the rate was only 35% for female applicants. In aggregate, it appears that there is a statistically significant bias against female applicants. However, when applications are disaggregated by department, the majority of 85 departments had no significant bias against either sex, 4 were biased against women, and 6 were biased against men. This apparent contradiction is resolved when one considers that women applied at higher frequencies to departments with lower overall acceptance rates. In aggregate, the acceptance rate for women appears significantly lower than for men only because this aggregate is proportionally weighted by the number of applicants to each department – so the aggregate rate for women overweighs (relative to men) departments that are overall harder to get into. Similar paradoxes occur in medical research – for instance, a treatment may appear more effective at curing cancer overall, but that effect disappears when the patients in the study are split by severity of the cancer.
The lesson from Simpson’s paradox is that aggregate metrics can lead to the wrong conclusions when one does not consider the composition of the aggregate. Statisticians classify such studies as missing confounding variables – what accounts for the differences in groups is something other than the treatment being studied. This phenomenon is often obvious ex post but can be hard to recognize, as in the UC Berkeley case: if researchers were to test a new cancer drug only on benign forms of cancer, clearly their mortality results would look better when compared to existing drugs.
Dan McCarthy et al.3 recently published a fascinating study demonstrating an aggregation paradox occurring in the construction of churn metrics frequently used by investors to study a company’s performance over time. The paradox is statistically interesting because the aggregation bias is extremely subtle, but it is also practically important because it can lead to the somewhat puzzling conclusions that contradict common investor assumptions. The bias implies that:
A decreasing aggregate churn rate (or inversely, an increasing retention rate) may not indicate that the long-term quality of a company’s revenue base is increasing.
A sudden increase in aggregate churn rate (or inversely, a sudden increase in retention rate) may be the result of an increase in new customers and not say anything about the quality of a company’s revenue base.
For clarity, aggregate churn rate (or inversely, retention rate) refers to a common but problematic construction of a very common business metric meant to measure the stickiness or longevity of customers with a subscription service or product. Churn rates are expressed as percentages (i.e., what percentage of customers left a service). Aggregate churn rates refer to the construction of this metric over an entire customer base. This is one of the most common reported formulations, especially in quarterly reports, financial statements, and investor updates. For instance, Netflix defines churn rate as “Churn is a monthly measure defined as customer cancellations in the quarter divided by the sum of beginning subscribers and gross subscriber additions, then divided by three months.”4 Similarly, Freshworks, a software company, defines a retention rate similarly when it explains that “To calculate net dollar retention rate as of a particular date, we first determine “Entering ARR [Annual Recurring Revenue],” which is ARR from the population of our customers as of 12 months prior to the end of the reporting period. We then calculate the “Ending ARR” from the same set of customers as of the end of the reporting period. We then divide the Ending ARR by the Entering ARR to arrive at our net dollar retention rate. Ending ARR includes upsells, cross-sells, and renewals during the measurement period and is net of any contraction or attrition over this period.”5 And, in fact, authoritative sources such as Salesforce6, Hubspot7, or popular blogs8 instruct prospective investors or operators to construct churn or retention metrics in more or less this manner: across the entire comparable customer base. Investors typically assume that decreasing churn rates over time are positive because they indicate increased customer stickiness and, therefore, increased lifetime value of the existing customer base.
Dan McCarthy et al. show that the common, aggregate construction of churn is problematic when compared over time, due to the varying sizes of customer acquisition cohorts. The authors illustrate the paradox by showing how a company, Hubble Contacts, can report consistently decreasing aggregate churn (i.e., each period, a smaller percentage of their customer base leaves) and yet each subsequent customer cohort has a materially worse retention curve (Figure below). The paradox will become apparent when revenue projections will lower (as the lifetime value of the customer base is progressively lower) despite the company reporting continually better and better churn metrics.
The paradox occurs when a fixed-period (i.e., 1-month, 12-month, etc.) aggregate churn rate is reported over time, with no regard to the relative customer cohort sizes. The problem is that the average age of a customer base changes at a non-constant rate because the size of customer cohorts (or equivalently, the customer acquisition rate) changes in size over time. This non-constant change in average customer age or, equivalently, different sized customer acquisition cohorts, is problematic because retention curves are, themselves, changing at non-constant rates. So, where each customer cohort is in their curve matters significantly to that cohort’s next period expected churn, and the aggregate churn metric – which will average across retention curves for each cohort, weighted by cohort size – will therefore change partially in proportion to the average customer age. The confounding variable, or missing grouping in other words, is the number of customers in each cohort.
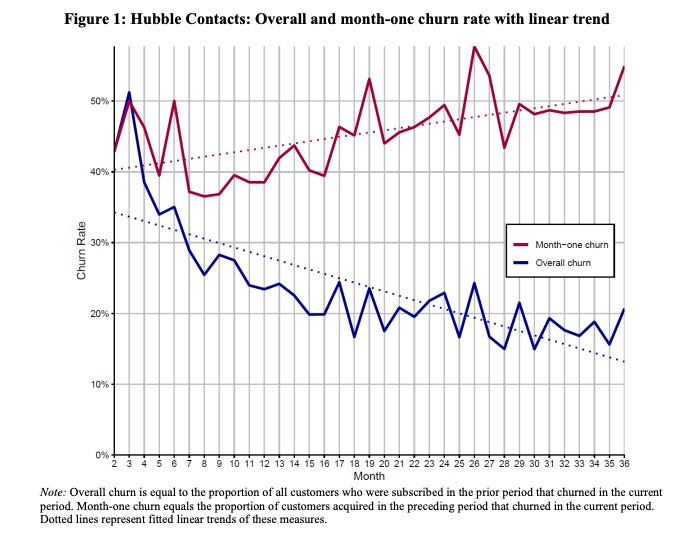
The corollary is that a sudden increase in churn rate may occur only when there is a sudden influx of customers (who immediately start at the steepest drop-off of their retention curve). The aggregate churn rate is weighted towards these new customers, and these are expected to churn at the highest rate.
The paper focuses on companies offering monthly consumer subscriptions; however, its findings are not specific to monthly subscriptions or to consumer companies. The bias is convenient to demonstrate in such conditions although it is generalizable to any type of aggregate churn measured at a fixed period and compared over time. Most software-as-a-service (SaaS) companies, for instance, will consider 12-month net dollar retention. They are not excused from this effect – annual changes in their NDR will still be driven by the blend of customer ages in their customer base; the resulting changes just show up a year later. A SaaS company can therefore report incrementally favorable results in their net dollar retention rates over time, while each subsequent cohort of customers has worse lifetime values.
Actually, apparently Mark Twain attributed this quote to Benjamin Disraeli, but there does not appear to be a source.
Salesforce - How to Calculate Customer Churn Rate and Revenue Churn Rate